
![]()
Databricks Databricks-Certified-Data-Engineer-Associate Exam Questions (Updated 2025) 100% Real Question Answers
Pass Databricks Databricks-Certified-Data-Engineer-Associate Exam Quickly With Prep4away
Databricks-Certified-Data-Engineer-Associate exam is an essential certification for data engineers who work with Databricks. Databricks-Certified-Data-Engineer-Associate exam measures the candidate's knowledge, skills, and abilities in Databricks architecture, data ingestion, data processing, data engineering, data storage, and data management. Databricks Certified Data Engineer Associate Exam certification is recognized globally and is a valuable asset for data engineers who want to advance their careers and demonstrate their proficiency in Databricks.
The GAQM Databricks-Certified-Data-Engineer-Associate (Databricks Certified Data Engineer Associate) Certification Exam is a challenging and highly respected certification for data professionals. It is designed to test individuals' knowledge and skills in data engineering, with a focus on the Databricks platform. Individuals who pass the exam will have a valuable certification that can help them advance their careers and increase their earning potential.
NEW QUESTION # 30
A data engineer only wants to execute the final block of a Python program if the Python variable day_of_week is equal to 1 and the Python variable review_period is True.
Which of the following control flow statements should the data engineer use to begin this conditionally executed code block?
- A. if day_of_week = 1 and review_period:
- B. if day_of_week == 1 and review_period:
- C. if day_of_week == 1 and review_period == "True":
- D. if day_of_week = 1 and review_period = "True":
- E. if day_of_week = 1 & review_period: = "True":
Answer: B
Explanation:
In Python, the == operator is used to compare the values of two variables, while the = operator is used to assign a value to a variable. Therefore, option A and E are incorrect, as they use the = operator for comparison. Option B and C are also incorrect, as they compare the review_period variable to a string value "True", which is different from the boolean value True. Option D is the correct answer, as it uses the == operator to compare the day_of_week variable to the integer value 1, and the and operator to check if both conditions are true. If both conditions are true, then the final block of the Python program will be executed. Reference: [Python Operators], [Python If ... Else]
NEW QUESTION # 31
Which of the following must be specified when creating a new Delta Live Tables pipeline?
- A. A location of a target database for the written data
- B. The preferred DBU/hour cost
- C. A path to cloud storage location for the written data
- D. A key-value pair configuration
- E. At least one notebook library to be executed
Answer: E
Explanation:
Option E is the correct answer because it is the only mandatory requirement when creating a new Delta Live Tables pipeline. A pipeline is a data processing workflow that contains materialized views and streaming tables declared in Python or SQL source files. Delta Live Tables infers the dependencies between these tables and ensures updates occur in the correct order. To create a pipeline, you need to specify at least one notebook library to be executed, which contains the Delta Live Tables syntax. You can also specify multiple libraries of different languages within your pipeline. The other options are optional or not applicable for creating a pipeline. Option A is not required, but you can optionally provide a key-value pair configuration to customize the pipeline settings, such as the storage location, the target schema, the notifications, and the pipeline mode. Option B is not applicable, as the DBU/hour cost is determined by the cluster configuration, not the pipeline creation. Option C is not required, but you can optionally specify a storage location for the output data from the pipeline. If you leave it empty, the system uses a default location. Option D is not required, but you can optionally specify a location of a target database for the written data, either in the Hive metastore or the Unity Catalog.
NEW QUESTION # 32
In which of the following file formats is data from Delta Lake tables primarily stored?
- A. Delta
- B. CSV
- C. JSON
- D. A proprietary, optimized format specific to Databricks
- E. Parquet
Answer: E
Explanation:
Delta Lake is an open source project that provides ACID transactions, time travel, and other features on top of Apache Parquet, a columnar file format that is widely used for big data analytics. Delta Lake uses versioned Parquet files to store your data in your cloud storage, along with JSON files as transaction logs and checkpoint files to track the changes and ensure data integrity. Delta Lake is compatible with any Apache Hive compatible file format, such as CSV, JSON, or AVRO, but it primarily stores data as Parquet files for better performance and compression. Reference: How to Create Delta Lake tables, 5 reasons to choose Delta Lake format (on Databricks), Parquet vs Delta format in Azure Data Lake Gen 2 store, What is Delta Lake? - Azure Databricks, Lakehouse and Delta tables - Microsoft Fabric
NEW QUESTION # 33
A data analyst has created a Delta table sales that is used by the entire data analysis team. They want help from the data engineering team to implement a series of tests to ensure the data is clean. However, the data engineering team uses Python for its tests rather than SQL.
Which of the following commands could the data engineering team use to access sales in PySpark?
- A. spark.delta.table("sales")
- B. spark.table("sales")
- C. SELECT * FROM sales
- D. There is no way to share data between PySpark and SQL.
- E. spark.sql("sales")
Answer: B
Explanation:
The data engineering team can use the spark.table method to access the Delta table sales in PySpark. This method returns a DataFrame representation of the Delta table, which can be used for further processing or testing. The spark.table method works for any table that is registered in the Hive metastore or the Spark catalog, regardless of the file format1. Alternatively, the data engineering team can also use the DeltaTable.forPath method to load the Delta table from its path2. References: 1: SparkSession | PySpark
3.2.0 documentation 2: Welcome to Delta Lake's Python documentation page - delta-spark 2.4.0 documentation
NEW QUESTION # 34
Which of the following describes the relationship between Gold tables and Silver tables?
- A. Gold tables are more likely to contain truthful data than Silver tables.
- B. Gold tables are more likely to contain more data than Silver tables.
- C. Gold tables are more likely to contain aggregations than Silver tables.
- D. Gold tables are more likely to contain valuable data than Silver tables.
- E. Gold tables are more likely to contain a less refined view of data than Silver tables.
Answer: E
NEW QUESTION # 35
A data engineer has been given a new record of data:
id STRING = 'a1'
rank INTEGER = 6
rating FLOAT = 9.4
Which of the following SQL commands can be used to append the new record to an existing Delta table my_table?
- A. UPDATE my_table VALUES ('a1', 6, 9.4)
- B. INSERT INTO my_table VALUES ('a1', 6, 9.4)
- C. INSERT VALUES ( 'a1' , 6, 9.4) INTO my_table
- D. my_table UNION VALUES ('a1', 6, 9.4)
- E. UPDATE VALUES ('a1', 6, 9.4) my_table
Answer: B
Explanation:
To append a new record to an existing Delta table, you can use the INSERT INTO statement with the VALUES clause. This statement will insert one or more rows into the table with the specified values.
Option A is the only code block that follows this syntax correctly. Option B is incorrect, as it uses the UNION operator, which will return a new table that is the union of two tables, not append to an existing table. Option C is incorrect, as it uses the INSERT VALUES statement, which is not a valid SQL syntax.
Option D is incorrect, as it uses the UPDATE statement, which will modify existing rows in the table, not append new rows. Option E is incorrect, as it uses the UPDATE VALUES statement, which is also not a valid SQL syntax. References: Insert data into a table using SQL | Databricks on AWS, Insert data into a table using SQL - Azure Databricks, Delta Lake Quickstart - Azure Databricks
NEW QUESTION # 36
Which of the following data workloads will utilize a Gold table as its source?
- A. A job that ingests raw data from a streaming source into the Lakehouse
- B. A job that cleans data by removing malformatted records
- C. A job that queries aggregated data designed to feed into a dashboard
- D. A job that enriches data by parsing its timestamps into a human-readable format
- E. A job that aggregates uncleaned data to create standard summary statistics
Answer: C
Explanation:
A Gold table is a table that contains highly refined and aggregated data that powers analytics, machine learning, and production applications. It represents data that has been transformed into knowledge, rather than just information. A Gold table is typically the final output of a medallion lakehouse architecture, where data flows from Bronze to Silver to Gold tables, with each layer improving the structure and quality of data. A job that queries aggregated data designed to feed into a dashboard is an example of a data workload that will utilize a Gold table as its source, as it requires data that is ready for consumption and analysis. The other options are either data workloads that will use a Bronze or Silver table as their source, or data workloads that will produce a Gold table as their output. References: Databricks Documentation - What is the medallion lakehouse architecture?, Databricks Documentation - What is a Medallion Architecture?, K21Academy - Delta Lake Architecture & Azure Databricks Workspace.
NEW QUESTION # 37
A new data engineering team has been assigned to work on a project. The team will need access to database customers in order to see what tables already exist. The team has its own group team.
Which of the following commands can be used to grant the necessary permission on the entire database to the new team?
- A. GRANT CREATE ON DATABASE team TO customers;
- B. GRANT USAGE ON CATALOG team TO customers;
- C. GRANT VIEW ON CATALOG customers TO team;
- D. GRANT USAGE ON DATABASE customers TO team;
- E. GRANT CREATE ON DATABASE customers TO team;
Answer: D
Explanation:
The correct command to grant the necessary permission on the entire database to the new team is to use the GRANT USAGE command. The GRANT USAGE command grants the principal the ability to access the securable object, such as a database, schema, or table. In this case, the securable object is the database customers, and the principal is the group team. By granting usage on the database, the team will be able to see what tables already exist in the database. Option E is the only option that uses the correct syntax and the correct privilege type for this scenario. Option A uses the wrong privilege type (VIEW) and the wrong securable object (CATALOG). Option B uses the wrong privilege type (CREATE), which would allow the team to create new tables in the database, but not necessarily see the existing ones. Option C uses the wrong securable object (CATALOG) and the wrong principal (customers). Option D uses the wrong securable object (team) and the wrong principal (customers). Reference: GRANT, Privilege types, Securable objects, Principals
NEW QUESTION # 38
A dataset has been defined using Delta Live Tables and includes an expectations clause:
CONSTRAINT valid_timestamp EXPECT (timestamp > '2020-01-01') ON VIOLATION DROP ROW What is the expected behavior when a batch of data containing data that violates these constraints is processed?
- A. Records that violate the expectation are added to the target dataset and recorded as invalid in the event log.
- B. Records that violate the expectation cause the job to fail.
- C. Records that violate the expectation are dropped from the target dataset and recorded as invalid in the event log.
- D. Records that violate the expectation are added to the target dataset and flagged as invalid in a field added to the target dataset.
- E. Records that violate the expectation are dropped from the target dataset and loaded into a quarantine table.
Answer: C
Explanation:
Explanation
With the defined constraint and expectation clause, when a batch of data is processed, any records that violate the expectation (in this case, where the timestamp is not greater than '2020-01-01') will be dropped from the target dataset. These dropped records will also be recorded as invalid in the event log, allowing for auditing and tracking of the data quality issues without causing the entire job to fail.
https://docs.databricks.com/en/delta-live-tables/expectations.html
NEW QUESTION # 39
A data engineer is using the following code block as part of a batch ingestion pipeline to read from a composable table:
Which of the following changes needs to be made so this code block will work when the transactions table is a stream source?
- A. Replace schema(schema) with option ("maxFilesPerTrigger", 1)
- B. Replace predict with a stream-friendly prediction function
- C. Replace "transactions" with the path to the location of the Delta table
- D. Replace format("delta") with format("stream")
- E. Replace spark.read with spark.readStream
Answer: E
Explanation:
Explanation
https://docs.databricks.com/en/structured-streaming/delta-lake.html
In the context of Databricks, when transitioning from batch processing to stream processing, one common change that needs to be made is replacing spark.read with spark.readStream. This modification is essential because spark.read is used for batch processing, while spark.readStream is used for stream processing. The rest of the code can often remain the same or require minimal changes. References: The information can be referenced from Databricks documentation on structured streaming: Structured Streaming Programming Guide.
NEW QUESTION # 40
A data engineer wants to create a data entity from a couple of tables. The data entity must be used by other data engineers in other sessions. It also must be saved to a physical location.
Which of the following data entities should the data engineer create?
- A. Table
- B. Database
- C. Function
- D. View
- E. Temporary view
Answer: A
Explanation:
A table is a data entity that is stored in a physical location and can be accessed by other data engineers in other sessions. A table can be created from one or more tables using the CREATE TABLE or CREATE TABLE AS SELECT commands. A table can also be registered from an existing DataFrame using the spark.catalog.createTable method. A table can be queried using SQL or DataFrame APIs. A table can also be updated, deleted, or appended using the MERGE INTO command or the DeltaTable API. Reference:
Create a table
Create a table from a query result
Register a table from a DataFrame
[Query a table]
[Update, delete, or merge into a table]
NEW QUESTION # 41
A data engineer is working with two tables. Each of these tables is displayed below in its entirety.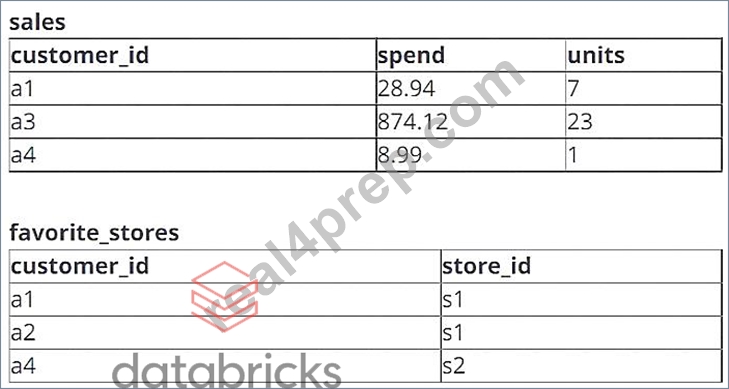
The data engineer runs the following query to join these tables together:
Which of the following will be returned by the above query?
- A. Option C
- B. Option E
- C. Option B
- D. Option D
- E. Option A
Answer: E
Explanation:
Option A is the correct answer because it shows the result of an INNER JOIN between the two tables. An INNER JOIN returns only the rows that have matching values in both tables based on the join condition. In this case, the join condition is ON a.customer_id = c.customer_id, which means that only the rows that have the same customer ID in both tables will be included in the output. The output will have four columns:
customer_id,name, account_id, and overdraft_amt. The output will have four rows, corresponding to the four customers who have accounts in the account table.
References: The use of INNER JOIN can be referenced from Databricks documentation on SQL JOIN or from other sources like W3Schools or GeeksforGeeks.
NEW QUESTION # 42
A data engineer has a Job that has a complex run schedule, and they want to transfer that schedule to other Jobs.
Rather than manually selecting each value in the scheduling form in Databricks, which of the following tools can the data engineer use to represent and submit the schedule programmatically?
- A. datetime
- B. pyspark.sql.types.TimestampType
- C. pyspark.sql.types.DateType
- D. There is no way to represent and submit this information programmatically
- E. Cron syntax
Answer: E
Explanation:
Cron syntax is a tool that can be used to represent and submit a complex run schedule programmatically. Cron syntax is a string of six fields that specify the frequency, date, and time of a job run. For example, the cron expression 0 0 12 * * ? means run the job at 12:00 PM every day. The data engineer can use the Databricks REST API to create or update a job with a cron schedule. The data engineer can also use the Databricks CLI to create or update a job with a cron schedule by using a JSON file that contains the cron expression. The other tools are either invalid or not suitable for representing and submitting a complex run schedule programmatically. Reference: Schedule a job, Jobs API, Databricks CLI, Cron expressions
NEW QUESTION # 43
Which of the following Git operations must be performed outside of Databricks Repos?
- A. Merge
- B. Clone
- C. Pull
- D. Push
- E. Commit
Answer: A
Explanation:
Databricks Repos is a visual Git client and API in Databricks that supports common Git operations such as commit, pull, push, branch management, and visual comparison of diffs when committing1. However, merge is not supported in the Git dialog2. You need to use the Repos UI or your Git provider to merge branches3. Merge is a way to combine the commit history from one branch into another branch1. During a merge, a merge conflict is encountered when Git cannot automatically combine code from one branch into another. Merge conflicts require manual resolution before a merge can be completed1. References: 4: Run Git operations on Databricks Repos4, 1: CI/CD techniques with Git and Databricks Repos1, 3: Collaborate in Repos3, 2: Databricks Repos - What it is and how we can use it2.
Databricks Repos is a visual Git client and API in Databricks that supports common Git operations such as commit, pull, push, merge, and branch management. However, to clone a remote Git repository to a Databricks repo, you must use the Databricks UI or API. You cannot clone a Git repo using the CLI through a cluster's web terminal, as the files won't display in the Databricks UI1. References: 1: Run Git operations on Databricks Repos | Databricks on AWS2
NEW QUESTION # 44
A data engineering team has two tables. The first table march_transactions is a collection of all retail transactions in the month of March. The second table april_transactions is a collection of all retail transactions in the month of April. There are no duplicate records between the tables.
Which of the following commands should be run to create a new table all_transactions that contains all records from march_transactions and april_transactions without duplicate records?
- A. CREATE TABLE all_transactions AS
SELECT * FROM march_transactions
INNER JOIN SELECT * FROM april_transactions; - B. CREATE TABLE all_transactions AS
SELECT * FROM march_transactions
INTERSECT SELECT * from april_transactions; - C. CREATE TABLE all_transactions AS
SELECT * FROM march_transactions
MERGE SELECT * FROM april_transactions; - D. CREATE TABLE all_transactions AS
SELECT * FROM march_transactions
UNION SELECT * FROM april_transactions; - E. CREATE TABLE all_transactions AS
SELECT * FROM march_transactions
OUTER JOIN SELECT * FROM april_transactions;
Answer: D
Explanation:
The correct command to create a new table that contains all records from two tables without duplicate records is to use the UNION operator. The UNION operator combines the results of two queries and removes any duplicate rows. The INNER JOIN, OUTER JOIN, and MERGE operators do not remove duplicate rows, and the INTERSECT operator only returns the rows that are common to both tables. Therefore, option B is the only correct answer. References: Databricks SQL Reference - UNION, Databricks SQL Reference - JOIN, Databricks SQL Reference - MERGE, [Databricks SQL Reference - INTERSECT]
NEW QUESTION # 45
A new data engineering team team. has been assigned to an ELT project. The new data engineering team will need full privileges on the database customers to fully manage the project.
Which of the following commands can be used to grant full permissions on the database to the new data engineering team?
- A. GRANT ALL PRIVILEGES ON DATABASE customers TO team;
- B. GRANT ALL PRIVILEGES ON DATABASE team TO customers;
- C. GRANT USAGE ON DATABASE customers TO team;
- D. GRANT SELECT CREATE MODIFY USAGE PRIVILEGES ON DATABASE customers TO team;
- E. GRANT SELECT PRIVILEGES ON DATABASE customers TO teams;
Answer: A
Explanation:
To grant full permissions on a database to a user, group, or service principal, the GRANT ALL PRIVILEGES ON DATABASE command can be used. This command grants all the applicable privileges on the database, such as CREATE, SELECT, MODIFY, and USAGE. The other options are either incorrect or incomplete, as they do not grant all the privileges or specify the wrong database or principal. References:
* GRANT
* Privileges
NEW QUESTION # 46
An engineering manager uses a Databricks SQL query to monitor ingestion latency for each data source. The manager checks the results of the query every day, but they are manually rerunning the query each day and waiting for the results.
Which of the following approaches can the manager use to ensure the results of the query are updated each day?
- A. They can schedule the query to refresh every 1 day from the SQL endpoint's page in Databricks SQL.
- B. They can schedule the query to refresh every 1 day from the query's page in Databricks SQL.
- C. They can schedule the query to refresh every 12 hours from the SQL endpoint's page in Databricks SQL.
- D. They can schedule the query to run every 12 hours from the Jobs UI.
- E. They can schedule the query to run every 1 day from the Jobs UI.
Answer: B
NEW QUESTION # 47
Which of the following approaches should be used to send the Databricks Job owner an email in the case that the Job fails?
- A. MLflow Model Registry Webhooks
- B. Setting up an Alert in the Notebook
- C. Setting up an Alert in the Job page
- D. There is no way to notify the Job owner in the case of Job failure
- E. Manually programming in an alert system in each cell of the Notebook
Answer: C
Explanation:
Explanation
https://docs.databricks.com/en/workflows/jobs/job-notifications.html
NEW QUESTION # 48
A data engineer has realized that they made a mistake when making a daily update to a table. They need to use Delta time travel to restore the table to a version that is 3 days old. However, when the data engineer attempts to time travel to the older version, they are unable to restore the data because the data files have been deleted.
Which of the following explains why the data files are no longer present?
- A. The VACUUM command was run on the table
- B. The TIME TRAVEL command was run on the table
- C. The HISTORY command was run on the table
- D. The OPTIMIZE command was nun on the table
- E. The DELETE HISTORY command was run on the table
Answer: A
Explanation:
The VACUUM command is used to remove files that are no longer referenced by a Delta table and are older than the retention threshold1. The default retention period is 7 days2, but it can be changed by setting the delta.logRetentionDuration and delta.deletedFileRetentionDuration configurations3. If the VACUUM command was run on the table with a retention period shorter than 3 days, then the data files that were needed to restore the table to a 3-day-old version would have been deleted. The other commands do not delete data files from the table. The TIME TRAVEL command is used to query a historical version of the table4. The DELETE HISTORY command is not a valid command in Delta Lake. The OPTIMIZE command is used to improve the performance of the table by compacting small files into larger ones5. The HISTORY command is used to retrieve information about the operations performed on the table. Reference: 1: VACUUM | Databricks on AWS 2: Work with Delta Lake table history | Databricks on AWS 3: [Delta Lake configuration | Databricks on AWS] 4: Work with Delta Lake table history - Azure Databricks 5: [OPTIMIZE | Databricks on AWS] : [HISTORY | Databricks on AWS]
NEW QUESTION # 49
A data engineer needs to apply custom logic to identify employees with more than 5 years of experience in array column employees in table stores. The custom logic should create a new column exp_employees that is an array of all of the employees with more than 5 years of experience for each row. In order to apply this custom logic at scale, the data engineer wants to use the FILTER higher-order function.
Which of the following code blocks successfully completes this task?
- A. Option C
- B. Option E
- C. Option B
- D. Option D
- E. Option A
Answer: E
Explanation:
Option A is the correct answer because it uses the FILTER higher-order function correctly to filter out employees with more than 5 years of experience from the array column "employees". It applies a lambda function i -> i.years_exp > 5 that checks if the years of experience of each employee in the array is greater than 5. If this condition is met, the employee is included in the new array column "exp_employees".
References: The use of higher-order functions like FILTER can be referenced from Databricks documentation on Higher-Order Functions.
NEW QUESTION # 50
Which of the following benefits is provided by the array functions from Spark SQL?
- A. An ability to work with time-related data in specified intervals
- B. An ability to work with data within certain partitions and windows
- C. An ability to work with an array of tables for procedural automation
- D. An ability to work with data in a variety of types at once
- E. An ability to work with complex, nested data ingested from JSON files
Answer: E
Explanation:
The array functions from Spark SQL are a subset of the collection functions that operate on array columns1. They provide an ability to work with complex, nested data ingested from JSON files or other sources2. For example, the explode function can be used to transform an array column into multiple rows, one for each element in the array3. The array_contains function can be used to check if a value is present in an array column4. The array_join function can be used to concatenate all elements of an array column with a delimiter. These functions can be useful for processing JSON data that may have nested arrays or objects. References: 1: Spark SQL, Built-in Functions - Apache Spark 2: Spark SQL Array Functions Complete List - Spark By Examples 3: Spark SQL Array Functions - Syntax and Examples - DWgeek.com 4: Spark SQL, Built-in Functions - Apache Spark : Spark SQL, Built-in Functions - Apache Spark : [Working with Nested Data Using Higher Order Functions in SQL on Databricks - The Databricks Blog]
NEW QUESTION # 51
A data engineer has developed a data pipeline to ingest data from a JSON source using Auto Loader, but the engineer has not provided any type inference or schema hints in their pipeline. Upon reviewing the data, the data engineer has noticed that all of the columns in the target table are of the string type despite some of the fields only including float or boolean values.
Which of the following describes why Auto Loader inferred all of the columns to be of the string type?
- A. Auto Loader cannot infer the schema of ingested data
- B. All of the fields had at least one null value
- C. Auto Loader only works with string data
- D. JSON data is a text-based format
- E. There was a type mismatch between the specific schema and the inferred schema
Answer: D
Explanation:
Explanation
JSON data is a text-based format that uses strings to represent all values. When Auto Loader infers the schema of JSON data, it assumes that all values are strings. This is because Auto Loader cannot determine the type of a value based on its string representation. https://docs.databricks.com/en/ingestion/auto-loader/schema.html Forexample, the following JSON string represents a value that is logically a boolean: JSON "true" Use code with caution. Learn more However, Auto Loader would infer that the type of this value is string. This is because Auto Loader cannot determine that the value is a boolean based on its string representation. In order to get Auto Loader to infer the correct types for columns, the data engineer can provide type inference or schema hints. Type inference hints can be used to specify the types of specific columns. Schema hints can be used to provide the entire schema of the data. Therefore, the correct answer is B. JSON data is a text-based format.
NEW QUESTION # 52
Which of the following statements regarding the relationship between Silver tables and Bronze tables is always true?
- A. Silver tables contain a more refined and cleaner view of data than Bronze tables.
- B. Silver tables contain aggregates while Bronze data is unaggregated.
- C. Silver tables contain less data than Bronze tables.
- D. Silver tables contain a less refined, less clean view of data than Bronze data.
- E. Silver tables contain more data than Bronze tables.
Answer: A
Explanation:
In a medallion architecture, a common data design pattern for lakehouses, data flows from Bronze to Silver to Gold layer tables, with each layer progressively improving the structure and quality of data. Bronze tables store raw data ingested from various sources, while Silver tables apply minimal transformations and cleansing to create an enterprise view of the data. Silver tables can also join and enrich data from different Bronze tables to provide a more complete and consistent view of the data. Therefore, option D is the correct answer, as Silver tables contain a more refined and cleaner view of data than Bronze tables. Option A is incorrect, as it is the opposite of the correct answer. Option B is incorrect, as Silver tables do not necessarily contain aggregates, but can also store detailed records. Option C is incorrect, as Silver tables may contain less data than Bronze tables, depending on the transformations and cleansing applied. Option E is incorrect, as Silver tables may contain more data than Bronze tables, depending on the joins and enrichments applied. Reference: What is a Medallion Architecture?, Transforming Bronze Tables in Silver Tables, What is the medallion lakehouse architecture?
NEW QUESTION # 53
Which of the following commands will return the location of database customer360?
- A. ALTER DATABASE customer360 SET DBPROPERTIES ('location' = '/user'};
- B. USE DATABASE customer360;
- C. DESCRIBE LOCATION customer360;
- D. DROP DATABASE customer360;
- E. DESCRIBE DATABASE customer360;
Answer: E
Explanation:
The command DESCRIBE DATABASE customer360; will return the location of the database customer360, along with its comment and properties. This command is an alias for DESCRIBE SCHEMA customer360;, which can also be used to get the same information. The other commands will either drop the database, alter its properties, or use it as the current database, but will not return its location12. Reference:
DESCRIBE DATABASE | Databricks on AWS
DESCRIBE DATABASE - Azure Databricks - Databricks SQL
NEW QUESTION # 54
A data engineer is using the following code block as part of a batch ingestion pipeline to read from a composable table:
Which of the following changes needs to be made so this code block will work when the transactions table is a stream source?
- A. Replace schema(schema) with option ("maxFilesPerTrigger", 1)
- B. Replace predict with a stream-friendly prediction function
- C. Replace "transactions" with the path to the location of the Delta table
- D. Replace format("delta") with format("stream")
- E. Replace spark.read with spark.readStream
Answer: E
Explanation:
To read from a stream source, the data engineer needs to use the spark.readStream method instead of the spark.read method. The spark.readStream method returns a DataStreamReader object that can be used to specify the details of the input source, such as the format, the schema, the path, and the options. The spark.read method is only suitable for batch processing, not streaming processing. The other changes are not necessary or correct for reading from a stream source. References: Structured Streaming Programming Guide, Read a stream, Databricks Data Sources
NEW QUESTION # 55
......
Databricks-Certified-Data-Engineer-Associate exam is a comprehensive exam that tests the individual's knowledge of Databricks and its various features. Databricks-Certified-Data-Engineer-Associate exam includes multiple-choice questions that require the individual to select the best answer from a list of options. Databricks-Certified-Data-Engineer-Associate exam also includes hands-on tasks that require the individual to demonstrate their ability to perform specific tasks using Databricks.
Real Databricks Databricks-Certified-Data-Engineer-Associate Exam Questions [Updated 2025]: https://prep4sure.real4prep.com/Databricks-Certified-Data-Engineer-Associate-exam.html